How Do AI Software Engineers Really Compare To Humans?


Current AI evaluation metrics fail to represent many aspects of real-world software engineering tasks.
Introduction
AI software engineers like Devin and SWE-agent are frequently compared to human software engineers. However SWE-bench, the benchmark upon which this comparison is made, only applies to Python tasks, most of which involve making single-file changes of 15 lines or less and relies solely on unit tests to evaluate their correctness. My aim is to give you a framework to assess if AI's progress against this benchmark is relevant to your organization's work.
If you’re an organization building mobile applications or work with Java, Go, Swift or Typescript then progress against SWE-bench by AI software engineers or models has limited use to you.
Additionally, changes made by AI software engineers often disregard the use of third-party libraries and coding conventions, which is particularly relevant for organizations managing larger scale codebases.
To enhance AI's ability to address bugs and features across non-Python engineering domains, we need to expand datasets and evaluation tools like SWE-bench horizontally to cover more languages and technologies. Furthermore, we must also expand vertically, benchmarking against larger tasks, such as features spanning multiple pull requests, requiring integration testing on real hardware for mobile applications or against databases for performance-related issues. At StepChange, we are actively tackling this challenge. If you are interested in collaborating, please reach out.
In this article, I'll highlight important information from the SWE-bench paper and explore the dataset's tasks, employing AI to summarize and categorize them. I'll explain both the tasks AI fails at and those it resolves successfully. I will also perform this analysis for the tasks Devin was evaluated on.
What’s SWE-bench?
SWE-bench is a dataset and evaluation tool, offering 2,294 tasks based on actual GitHub issues and pull requests drawn from open source Python projects.

How Big Are The Tasks In SWE-bench?
The paper accompanying SWE-bench contains some high level information about the size of tasks present in the dataset which I have summarized below:
- Problem Description Size: The median task in the SWE-bench dataset gives a problem description for a task of 140 words.
- Codebase Size: The median task involves a codebase with close to 1,900 files and 400,000 lines of code.
- Reference Task Solutions: The reference solution provided usually modifies a single function within one file changing ∼15 lines.
- Task Evaluation: For each task, there is at least one fail-to-pass test which was used to test the reference solution, and 40% of tasks have at least two fail-to-pass tests. These tests evaluate whether the model addressed the problem in the issue. In addition, a median of 51 additional tests run to check whether prior functionality is properly maintained.
Looking through the tasks and their original PRs shows they're quite small, something a skilled engineer could handle quickly, in at most a couple of days. Here is an example of one feature Devin successfully completed to give you a flavor for what they are like:
- Feature Summary: The issue is a feature request to allow overriding of deletion widget in formsets, similar to how ordering_widget and get_ordering_widget() were introduced in Django 3.0.
- Fixes: Original PR, Devin’s PR
More are highlighted in my report on Devin's successes and failures. These tasks don't really show if an AI can take on bigger projects that stretch over several sprints, which is a key part of a software engineer's job.
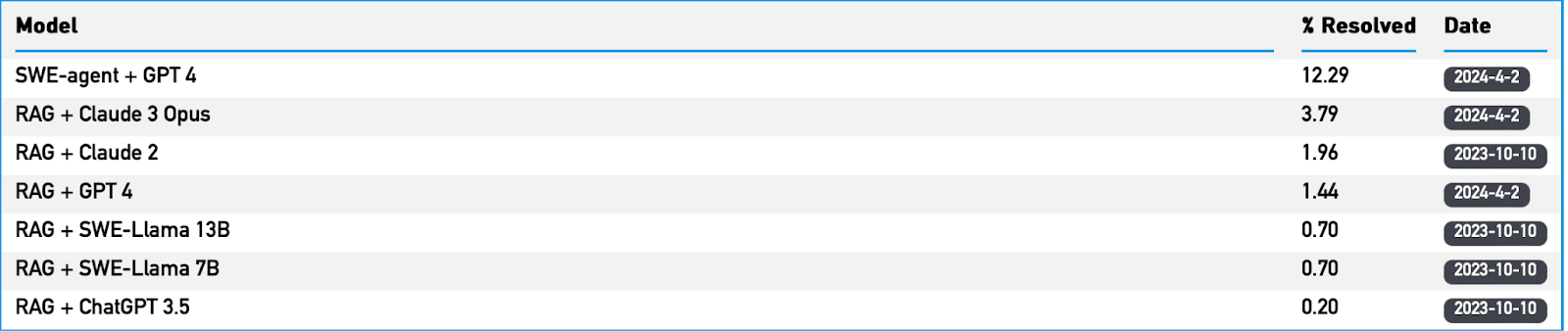
How Did Claude 2 and GPT 4 Perform Against SWE-bench?
At the time the paper was published, Claude 2 was the best performing model and it only resolved around 4.8% of issues with oracle retrieval. Oracle retrieval gives the LLM files known to resolve an issue in addition to the problem statement; this is less realistic because engineers don't usually know which files will need edits in advance. Without oracle retrieval Claude 2 was only able to resolve 1.96% of these issues.
Understanding How Model Limitations Apply To SWE-bench
The SWE-bench paper spotlighted a number of tasks and used them to highlight themes the researchers saw while analyzing the evaluation results:
- Models struggle with multi-line and multi-file changes: Models are more adept when the required fix is relatively short, and need help with understanding the codebase in an efficient manner.
- Models ignore an organization's working style: Code produced often didn't follow the project's style. One example highlighted using its own Python solution over using built in functions for handling things like string formatting. This would likely not be well-received by a human reviewer due to its inconsistency with the rest of the codebase.
- Use Of Libraries: Significant use of additional modules from other parts of the codebase itself and third party libraries were noted as cause of model failure. This came up for a task from the sphinx-doc/sphinx repository, where a model is asked to write logic to fix a case where the title is incorrectly being rendered. This example highlights the importance and potential for training language models and designing inference procedures that allow for the automated discovery of such information.
- Contextual Awareness: The model struggled with tasks that needed an understanding of how changes in one part of the code affect the rest. For example, in scikit-learn, the model had to correct an issue where outputs were flipped incorrectly. It failed because, beyond fixing the immediate problem, it didn't consider how other parts of the code relied on the function it was changing. This highlights the challenge of ensuring a model understands the wider code context, which is crucial but difficult.
- Tasks with images: Models struggled with problems containing images due to a lack of multimodal capabilities and or integration with external tools to process images. Debugging real software issues often involve digesting images. Beyond the SWE-bench tasks, additional problems in software engineering, such as interpreting system design diagrams, user interface specifications, or user feedback might be challenging.
An important difference to note between models being tested with SWE-bench and AI software engineers like Devin and SWE-agent is that the latter are iterative. Devin can execute multi-step plans to receive feedback from the environment, i.e they can iterate on errors like human software engineers whereas the models just submit their solution and don’t get a chance to incorporate feedback.
What Are Examples Of These Tasks?
At StepChange one of things we specialize in is Django web application performance, Django is also the biggest group of tasks in the dataset. As such I decided to write some scripts using GPT4 and Langchain to categorize, tag and summarize all of the Django related tasks in the dataset. You can find them here as well as a report summarizing all of the Django tasks Devin failed and passed here. It contains links to the original PR that fixed the issue, the diff generated by Devin and stats about diff sizes.
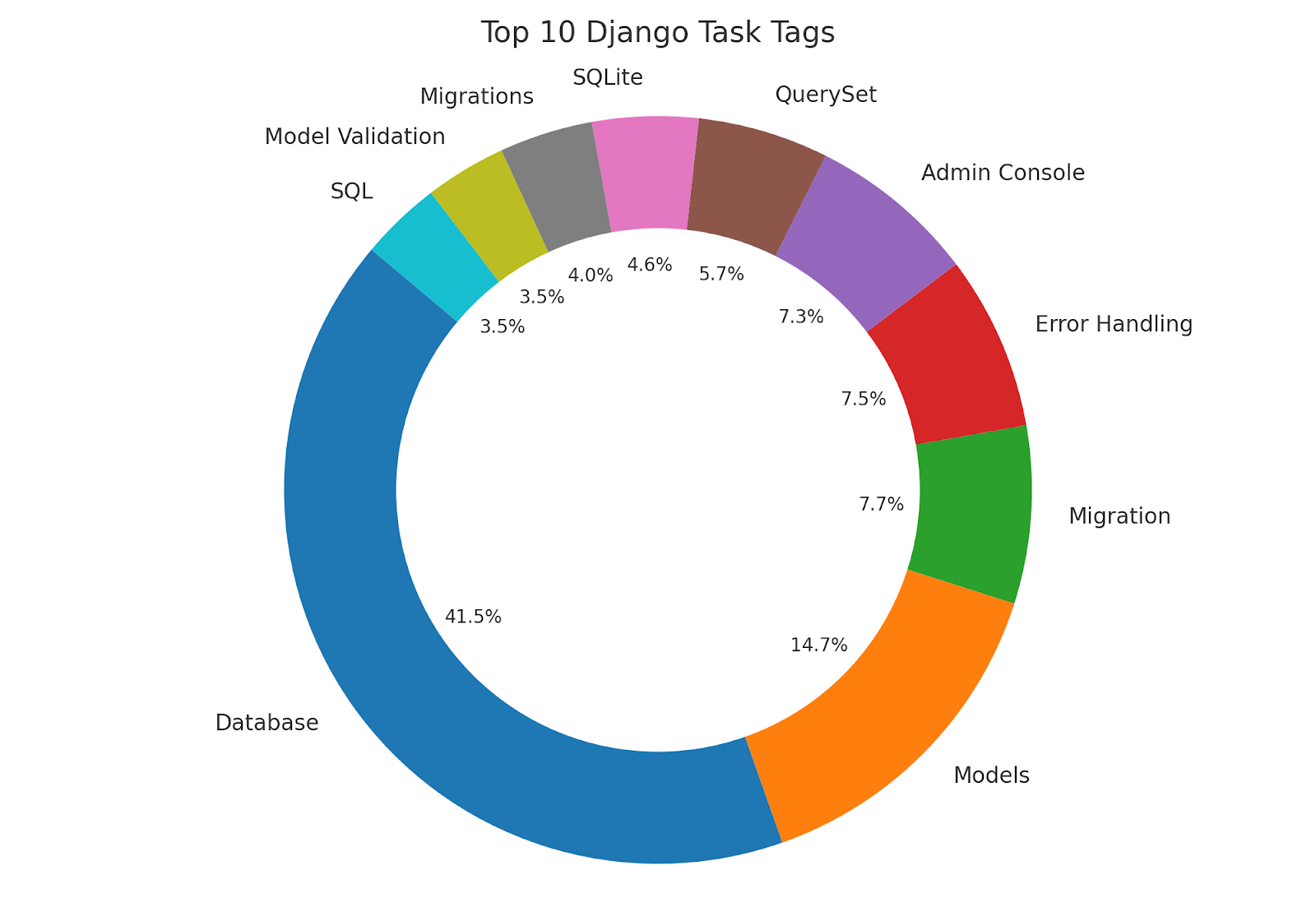
Reviewing the tasks tagged by GPT4 based on their summaries, we see that 41% of the tasks are tagged as being to do with databases with a large number of the other tags, such as models, model validation, SQL and SQLLite being related topics.
How Did Devin The AI Software Engineer Perform Against SWE-bench?
The team behind Devin published a technical report where they linked to a github repo containing the results of their evaluation against SWE-bench. Devin successfully completed 13.86% of these tasks, this outperforms the recently released open source SWE-agent which completes 12.29% of issues on the full test set. Going from 1.96% to 13.86% in six months is impressive progress.
An interesting point brought up by the Cognition Labs team in their technical report was when they provided Devin with the final unit test(s) along with the problem statement the successful pass rate increased to 23% out of 100 sampled tests. While in most cases it’s not realistic to have unit tests before code is written, in scenarios such as migrating from one language to another (e.g PHP to Next.js) unit tests could be generated from the legacy codebase.
One thing to note is that Cognition Labs, the team behind Devin and the team behind SWE-bench tested with a randomly chosen 25% of the SWE-bench test set. In the case of Devin this was done to reduce the time it takes for the benchmark to finish. The team behind the SWE-bench paper did the same thing for GPT-4; they used a 25% random subset of SWE-bench in the “oracle” and BM25 27K retriever settings. They claimed this was due to budget constraints.
Running the full SWE-bench evaluation takes hours because each task involves installing and deleting the tested repo and running multiple unit tests. If you want to do this without spending money on GPT-4 you can download the generated results from Claude and the GPTs here.
How Did Devin The AI Software Engineer Perform Against Django Tasks?
Devin was able to complete 19.19% of the Django tasks it attempted. The tasks in this subset were from between October 2015 to July 2023 with the majority of them being bugs.
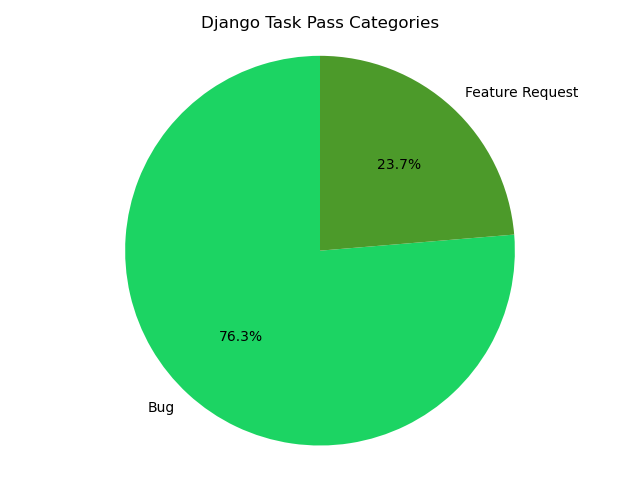
Devin's performance on SWE-bench tasks reveals a pattern of struggle with complex changes, particularly those requiring alterations across multiple files or exceeding 15 lines of code, mirroring challenges faced by models in the SWE-bench study.
In tasks that it failed, 95 had more than 1 file changed and 230 had more than 15 lines changed. In contrast to the tasks it successfully completed 11 had more than 1 file changed and 18 had more than 15 lines changed. Implying that like the models tested by SWE-bench, Devin struggled with larger changes spanning multiple files. Here are some examples of tasks Devin successfully completed to give you a flavor for what they are like:
- Bug Summary: The issue is about the TruncDate and TruncTime functions in Django not correctly handling timezone information passed to them. The functions are supposed to use the passed timezone info object, but they are instead using the return value from get_current_timezone_name() unconditionally.
- Fixes: Original PR, Devin’s PR
- Bug Summary: The class preparation for lazy() is not being cached correctly. This makes functions like gettext_lazy, format_lazy and reverse_lazy slower than they should be.
- Fixes: Original PR, Devin’s PR
At the time of writing this article the authors of SWE-bench had just released an open source competitor to Devin, SWE-agent which achieved a 12.29% resolve rate on the full test set. They will be releasing a paper on Apr 10, 2024, if you are interested in me doing a similar deep dive into their results please let me know by liking and sharing my article on X/twitter (my handle is htormey).
Conclusion
AI Software Engineers like Devin and SWE-Agent are getting a lot of attention right now, with huge potential and some very impressive demos. However it is critical to understand the benchmarks they are working against to evaluate them in real world scenarios and what their limitations are.
As an example, AI models like GPT-4 often struggle to keep up with API changes in third party libraries that update frequently. From my own experience, trying to use AI to generate code leveraging fast moving projects like LangChain or Next.js can be frustrating because the suggestions you get are often out of date. Hence the need for better benchmarks that are updated frequently.
It’s still early days for AI Software Engineers. I think within the next 2-3 years, AI will be able to handle debugging and multi-line code changes effectively across large codebases. This advancement will transform software engineers' roles from focusing on detailed coding tasks to prioritizing oversight and orchestration.
I believe this transition will be more significant than others I have made in my career such as from low-level to high-level programming languages. I don’t believe it will eliminate the need for human software expertise.
Engineers will still require a solid technical foundation to clearly define project requirements, strong logical reasoning skills to navigate complex issues, and the capacity to correct AI errors.
They will also play a crucial role in the iterative processes of building, testing, and debugging, now with AI as a tool in their arsenal. Furthermore, the development landscape will adapt, with new frameworks and tools being introduced to streamline the collaboration between engineers and AI.
Thanks to Niall O'Higgins, Gergely Orosz, Carl Cortright, Greg Kamradt, Nader Dabit for reviewing and providing feedback